|
【本期分析师介绍】希音老师,《数据分析学堂》金牌分析师,对eviews的时间序列、ARMA、VAR、VECM、ARCH、GARCH等操作有深入的研究和实战经验,累计服务客户1000+。今天邀请希音老师给大家分享eviews的详细操作步骤。长文预警!可在文末联系麻瓜学姐要PDF文档,更方便阅读,10G独家干货等你来拿!
AR-MA模型是一类常用的是随机时序模型。由Box和Jenkins创立,亦称B-J方法。它是一种精度较高的时序短期预测,其基本思想是,某些时间序列是依赖于时间t的一组随机变量。构成该时序的单个序列制虽然具有不确定性。但整个序列的变化却有一定的规律性。可以用相应的数学模型定制描述。通过对该数学模型的分析研究。能够本质地认识时间序列的结构与特征,达到最小方差意义下的最优预测。
本文章主要使用EVIews对构建ARMA模型,进行简单认识,由于对于所有的平稳时间序列都可以转化成MA形式。由于MA在可逆条件可以转化成AR形式。所以我们对平稳时间序列可以使用ARMA形式构建模型,进行预测。
一、 平稳性检验(单位根检验)
Eviews有多重检验平稳性的单位根检验,本文采用ADF进行采用检验,采用某国1960-1993年的GNP平减指数的季度数据,共136个观测值,首先对变量进行变换,得到其通货膨胀率,在EVIEWS的命令行中输入:genr pi=d(log(p))其中p指的是GNP指数,pi指的是通货膨胀率,genr是generate的缩写,为生成一个新变量,也可以使用series进行生成新变量,log(p)是自然对数函数,进行d(*),是指对变量*进行一阶差分。
生成变量以后,选中变量pi,双击打开,点击右上角的View,然后点击Unit root test那一项,进入页面图如下:
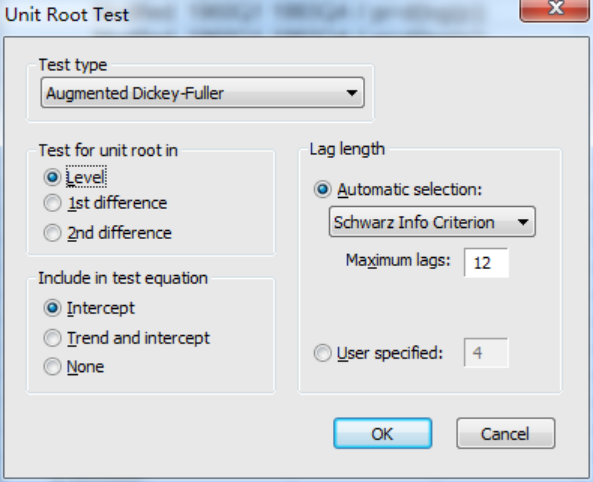
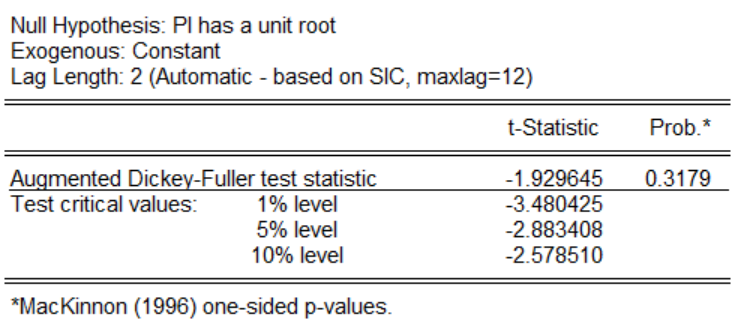
其中test type为检验单位根的类型,我们选中ADF检验(默认状态),在include in test equation这一项中为ADF检验的三种形式,lag length为滞后阶数,一般采用系统默认,在test for unit root in是对原数据进行单位根检验(level),还是对一阶差分进行单位根检验(1st difference),还是二阶差分进行单位姑娘检验(2st difference),本文先对原数据进行差分。关于三种形式,可以使用以下方法,分别对三种形式进行一一检验,只要有一个拒绝存在单位根的原假设,那就说明时间序列是平稳的。点击ok以后,发现三种形式下p值大于0.1,不能拒绝原假设,因此原时间序列不平稳,下图为带有截距项的示例图:
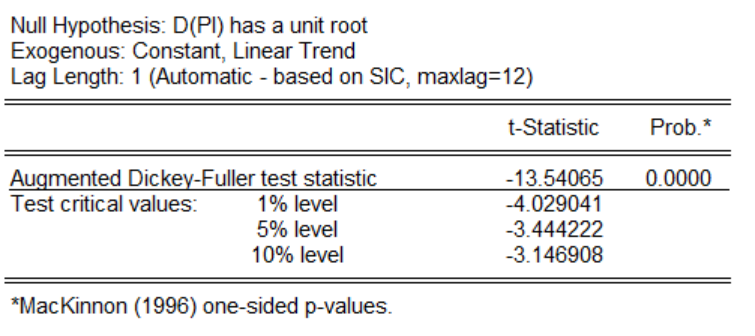
然后再对一阶差分下。进行单位根检验,检验结果发现,三种形式下的p值为0.0000因此拒绝存在单位根的原假设,所以一阶差分以后的时间序列是平稳的,可以对其进行构建ARMA模型。下图为带有时间趋势项和截距项的结果展示图:
二、 确定ARMA中的最大滞后阶数p和q
采用画样本相关系数图和偏自相关系数图来确定,在双击打开pi后,点击view,然后在点击correlogram,进行画相关图的页面:
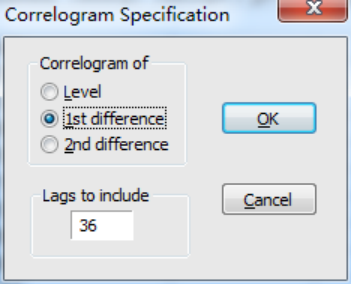
由于我们已经确定原数据是不平稳的额,一阶差分以后数据时平稳的,因此在这里使用第二个选项,对其一阶差分以后的时间序列进行研究,点击ok以后,出现如下相关图:
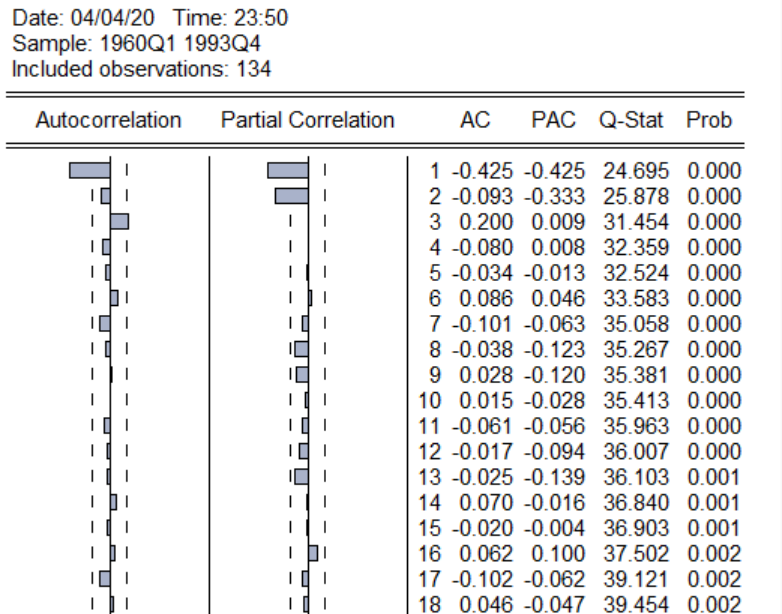
左边的为AC图(自相关图),PAC为右边图(偏自相关),确定最大滞后阶数的法则为图中的AC和PAC下方的小长方形的连续多少个超过两条虚线(两虚线被称为随机区间),图中PAC下方可以明显看出连续两个超出随机区间,因此可以采用Pmax为2,而AC下方的连续一个超出随机区间,因此可以采用qma为1。
三、 使用信息准则最小化原理确定最佳ARMA模型
P的最大值为2,q的最大值为1,因此可以有以下4种组合ARMA(1,0),ARMA(1,1),ARMA(2,0),ARMA(2,1),通过信息准则筛选出最优模型,以下在EVIEWS命令行中输入:
Ls d(pi)ar(1)
Ls d(pi) ar(1) ma(1)
Ls d(pi)ar(1)ar(2)
Ls d(pi)ar(1)ar(2)ma(1)
以上是四种模型的回归操作,这里对四种回归结果进行展示,根据信息准则(在图中为AIC,SC,HQ等),通过比较哪一个模型的这三个指标最小,就选哪一个模型,如果三个指标有大有小,采用投票原则,那个模型中三个指标最小的个数多就选那个。
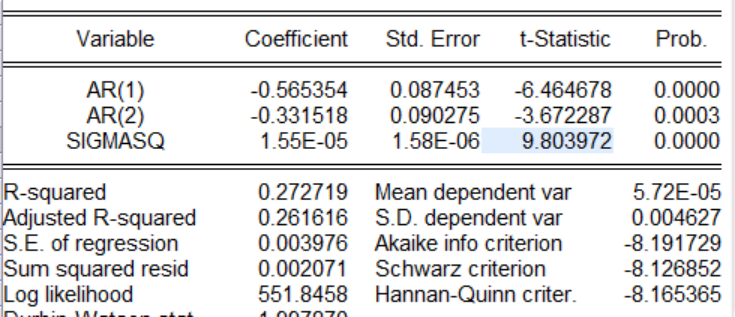
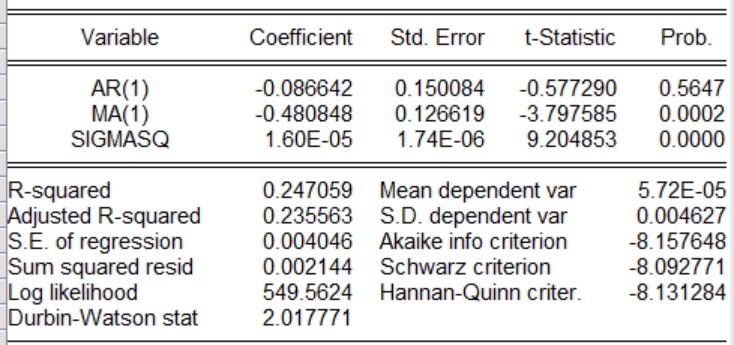
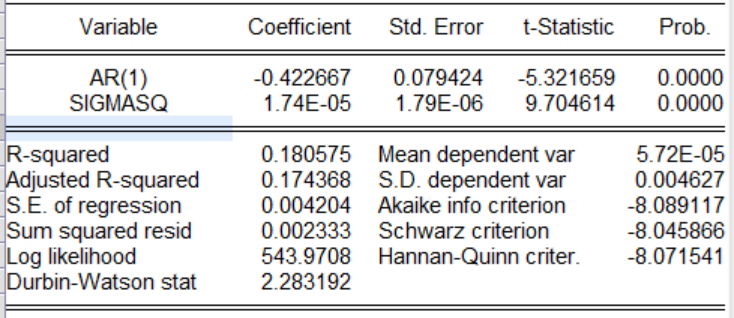
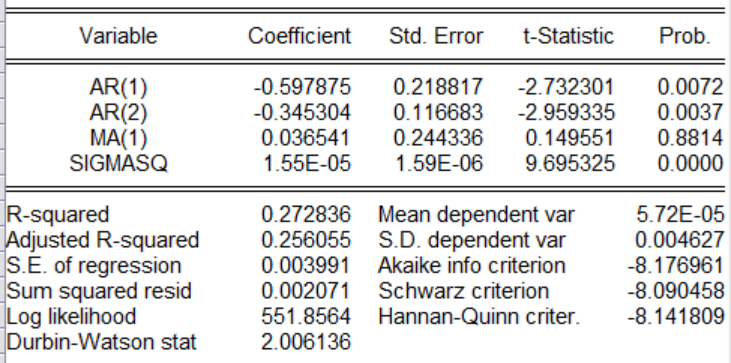
有图可以知道ARMA(2,1)模型中AIC,SC,HQ是最小的个数是最多的。因此采用ARMA(2,1)模型。
四、 白噪声检验
在构建这个模型时,我们假设模型的误差的序列无关的,因此我们有必要在构建模型以后进行误差的序列相关性检验,以此来说明模型构建的良好,如果序列之间不存在序列相关性,我们就称之为白噪声,就是认为该序列已经没有任何可以提取的信息了。对于白噪声的检验,可以采用Q统计量的方法,具体操作如下图:
在回归以后的表中,点击右上角的view,然后选中Residual diagnostics,在选第一个带有Q的,点击以后,选滞后阶数,你可以自定义也可以默认,采用默认方式以后,得到下图:
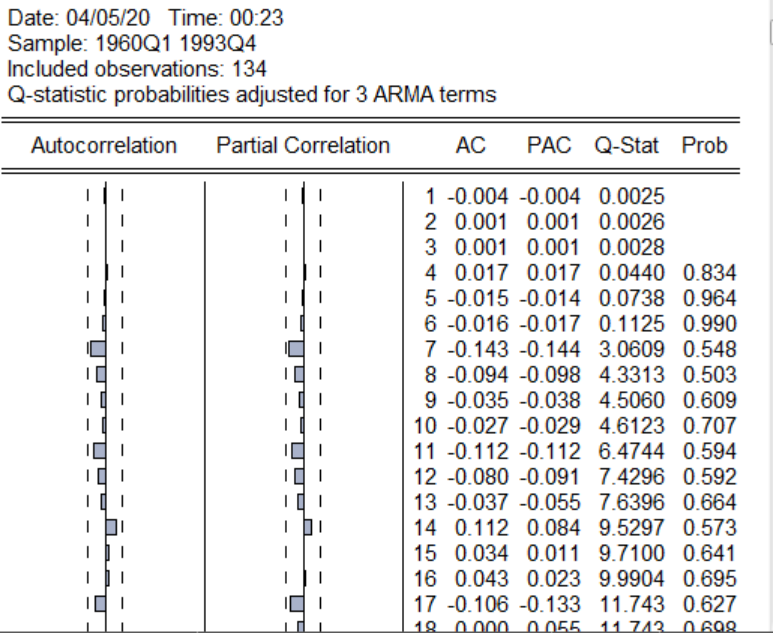
Q-star为Q统计量的值,prob为Q统计量的相伴概率,由于我们的样本数为136,最大滞后阶数m可以取[136/10]或者[],采用m为13,在表中寻找13行所对应的Q统计量和p值,分别为7.6396,0.664,。这个p值告诉我们在10%的显著性水平之下,我们不能拒绝序列不存在相关性的原假设,因此可以认为最后的检验是序列是不存在相关性的,白噪声检验通过,因此我们的模型时构建比较优良的。
五、 短期预测
预测分为样本内预测和样本内预测,预测的形式又可以分为静态预测和动态预测,其中样本内预测就是根据某种预测方式对其样本内的一段时间子区间进行预测,然后通过对比预测值和真实值之间的差距,这可以用一些指标(比如RMSE,MAPE)来衡量预测的好与坏,样本外需要先扩展样本区间,在进行样本外预测。静态预测每一期时需要用到上期的真实值,而动态预测用到的是其预测值或者说是拟合值,所以静态预测,一般只能预测样本为1期,而动态预测不受限制。下面对预测进行简单展示:
1.首先调整样本数,双击Range,然后对出现的页面中1993改成1994,这样我们就准备连续预测四期;
2.在回归页面表中,点击forcast,然后出现以下页面;
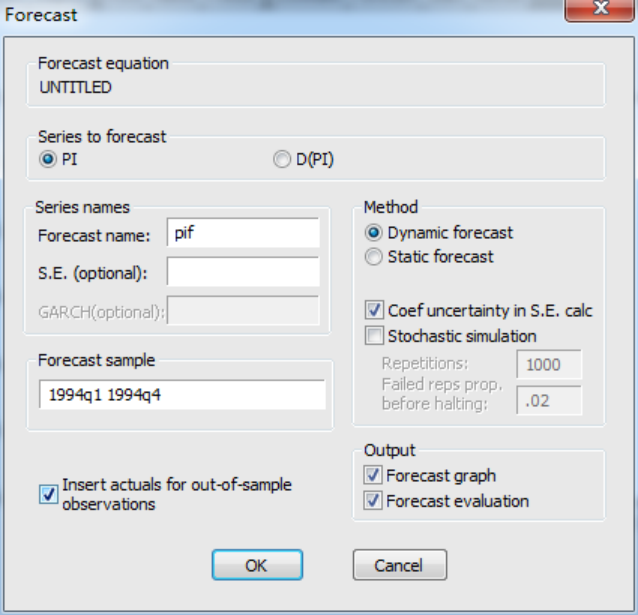
由于我们是通过对pi的一阶差分呢进行建立ARMA模型的,但是由于我们预测的是pi,即前面所说的通货膨胀率,因此选中pi,然后series names中forecast name为pif,这是系统默认的,如果你想预测某个序列,那么预测出来以后的序列名会在元序列多一个f,当然你也可以自定义。然后是forecast sample,预测样本区间选为1994第一季度到1994年第二季度,我们选中动态预测,dynamic forecast,之后点击ok。
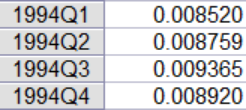
3.然后点击工作区中的pif序列,打开以后,寻找最后四期,结果如下图所示:
当然你也可以尝试静态预测,样本内预测,其操作大体类似,本文就不再一一赘述。
往期推荐
SPSS经典案例 | 小白必看!方差分析、T检验、相关分析、因子分析,上财博士手把手教你套模板!
stata经典案例 | 初学者必看!面板数据、广义矩估计、var模型、logit模型回归详细操作步骤
还在为毕业论文数据处理头秃?!喏,秘籍给你,红包也给你(文末有惊喜)

扫码关注小数,每天一篇精选干货!
[你长那么好看,文末点个在看再走呗】
|